
Figure 1
Figure 1. The Power of Sound (TPoS) is a novel framework that generates audio-reactive video sequences. Built upon the Stable Diffusion model, our model first generates an initial frame from a user-provided text prompt (e.g. "a photo of a beautiful beach with a blue sky"), then reactively manipulates the style of generated images corresponding to the sound inputs (e.g. an audio sequence of fireplace). Our model is indeed able to generate a frame conditioned on semantic information of the sound (see 1st and 2nd rows where images are manipulated driven by sound inputs such as fireplace or wave sound), while realistically dealing with temporal visual changes conditioned on changes of sound, e.g., increasing magnitude of sounds (see second row) or wave $\rightarrow$ fireplace (see last row). TPoS creates visually compelling and contextually relevant video sequences in an open domain.
Abstract
In recent years, video generation has become a prominent generative tool and has drawn significant attention. However, there is little consideration in audio-to-video generation, though audio contains unique qualities like temporal semantics and magnitude. Hence, we propose The Power of Sound (TPoS) model to incorporate audio input that includes both changeable temporal semantics and magnitude. To generate video frames, TPoS utilizes a latent stable diffusion model with textual semantic information, which is then guided by the sequential audio embedding from our pretrained Audio Encoder. As a result, this method produces audio reactive video contents. We demonstrate the effectiveness of TPoS across various tasks and compare its results with current state-of-the-art techniques in the field of audio-to-video generation.
Method
Inference
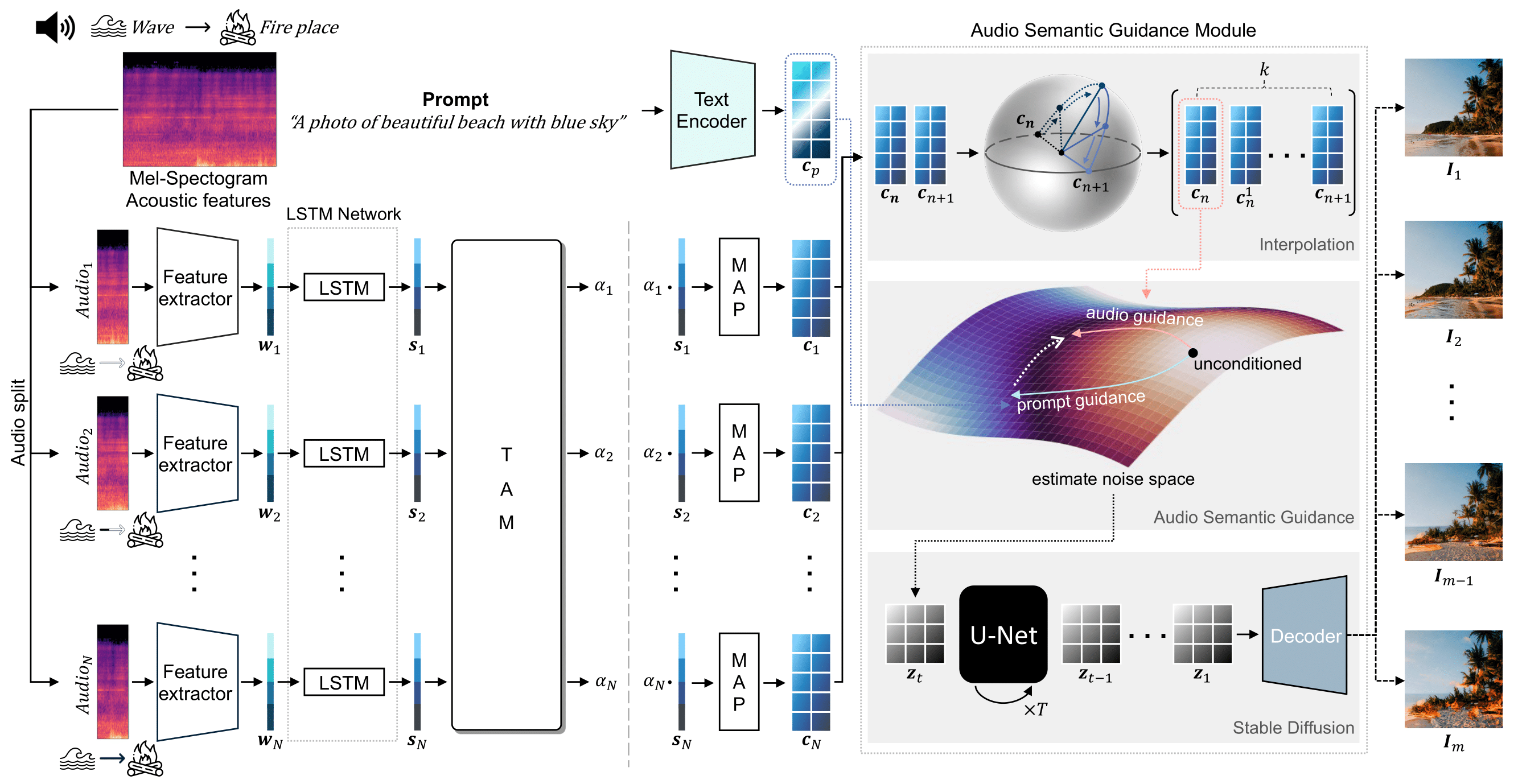
Figure 3
Figure 3. An overview of our proposed TPoS model. Our model consists of two main modules: (i) Audio Encoder, which produces a sequence of latent vectors, encoding temporal semantics of audio input by utilizing CLIP space and highlighting the important temporal features and (ii) Audio Semantic Guidance Module, which is based on the diffusion process, generating video frames that are temporally consistent and audio-reactive.
Train
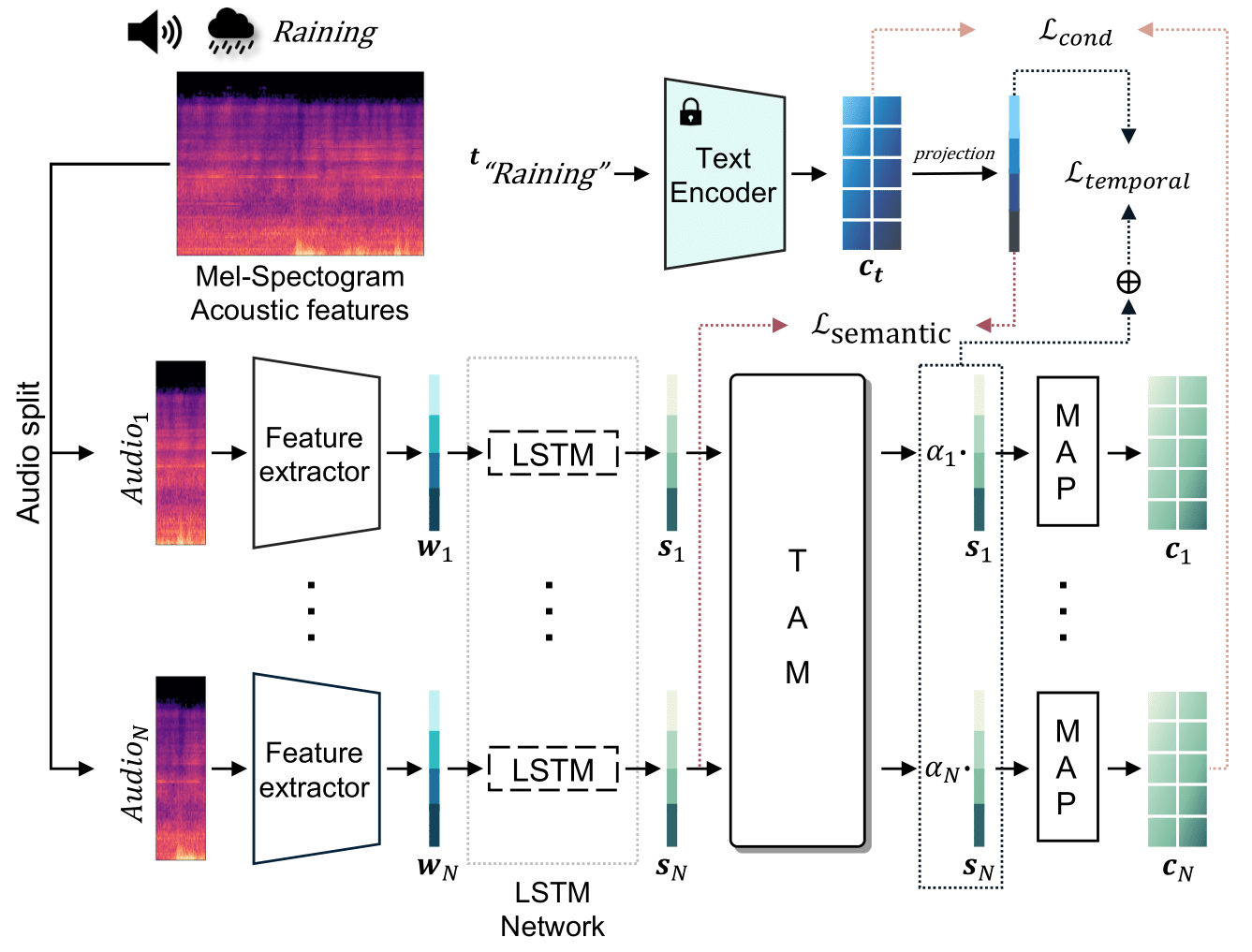
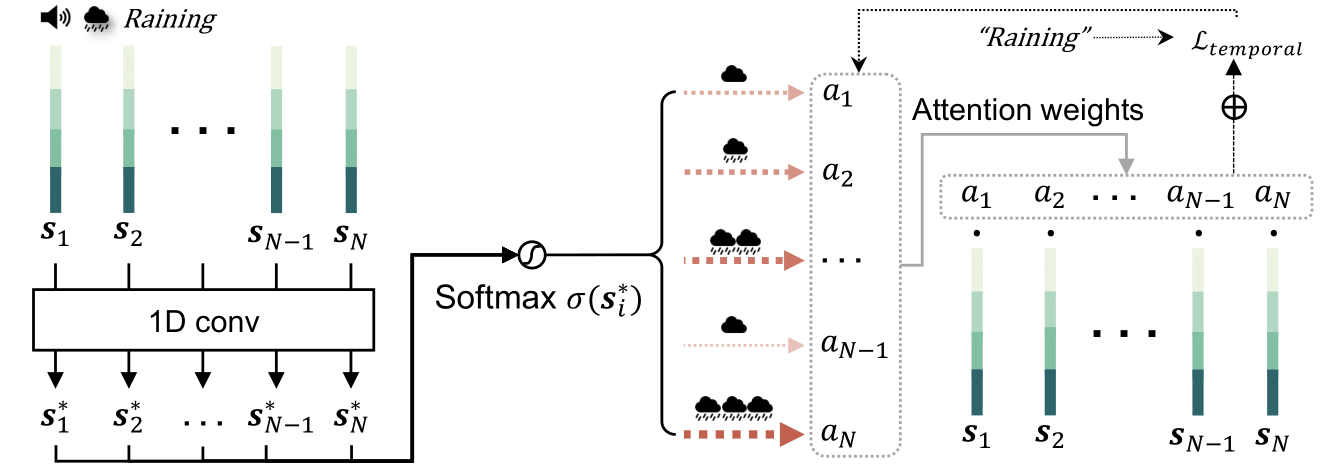
Figure 4. An overview of our Audio Encoder training process. Our model generates temporally-encoded audio embeddings with an LSTM layer and Temporal Attention Module (TAM). Audio input is partitioned into $N$ segments, and each of these is encoded and used as a condition to manipulate audio-reactive video sequences (e.g. light rain $\rightarrow$ heavy rain). This is done by our Mapping Module (MAP), which maps the audio embedding to the latent space of Stable Diffusion.
Figure 5. Details of our Temporal Attention Module (TAM). Temporal Attention Module effectively captures the important audio segments (e.g. harsh raining sound) as attention weights, which are guided by CLIP's text embedding (e.g. "raining") in training phase and express the magnitude of audio in test phase.
Generation Results

Prompt: A photo of beautiful park with sky

Prompt: A photo of landscape with sky

Prompt: A photo of landscape with sky

Prompt: A 3 d render of a garden, with a dreamy ultra wide shot

Prompt: A photo of beautiful garden with sky

Prompt: A photo of beautiful garden with sky

Prompt: A fountain in the garden
Face Example
Prompt: A photo of the face of a woman/manComparison
| Prompt: A photo of deep in the sea | Prompt: A photo of firewood in the forest | Prompt: A photo of volcano |
| Ours (Prompt) |

|

|

|
| 🔊 underwater bubbling | 🔊 fire crackling | 🔊 explosion |
| Ours |
| Sound2Sight |
| CCVS |
| TraumerAI |
| Lee et al |
BibTeX
If you use our code or data, please cite:
@inproceedings{jeong2023power,
title={The Power of Sound (TPoS): Audio Reactive Video Generation with Stable Diffusion},
author={Jeong, Yujin and Ryoo, Wonjeong and Lee, Seunghyun and Seo, Dabin and Byeon, Wonmin and Kim, Sangpil and Kim, Jinkyu},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={7822--7832},
year={2023}
}